搜尋結果頁面將面臨 25 年來最大改革
Google 每年都會在 I/O 開發者大會上公布搜尋與 AI 的最新方向,而在 2026 年的會議中,搜尋系統被視為迎來 25 年來最大一次結構性重構,主要集中在三大核心變革:
1.搜尋框 25 年來最大改版:AI Search

過去 Google 首頁就是一個白框,使用者必須把複雜的想法、疑惑濃縮成 2-3 個「關鍵字」。現在,這個框會隨輸入內容動態變大,使用者可以直接上傳圖片、長影片、檔案、甚至把整個 Chrome 分頁丟進去,用聊天的方式下達超長、超複雜的指令。
2.資訊代理人:Information Agents
還記得這幾年被反覆提到的「AI Agents」嗎?從國民爸爸黃仁勳的預告,到 LLM 大型語言模型的出現,本質其實都指向同一件事:接下來的 AI 不再只是回答問題,而是開始「替你完成任務」。
Google 同樣把這項科技應用在搜尋引擎裡,讓搜尋從單純的「查詢工具」,正式進化為「代理人網路(Agentic Web)」的全新入口。
用戶只要設定一個目標(例如:幫我監控今年全台排隊名店的端午節粽子禮盒優惠),AI 就會 24 小時在背景爬取全網的部落格、新聞、社群與即時數據,只要一有變動就會主動彙整並通知用戶。
3.AI Mode 核心升級:Gemini 3.5 Flash 成為標配
Google 搜尋的 AI Mode 與 AI Overviews 摘要,全面改由新一代 Gemini 3.5 Flash 驅動。它在處理複雜程式、邏輯推理與多輪對話的速度提升了 4 倍,消除了過去的生成延遲,讓 AI 搜尋的體驗變得像跟真人對話一樣流暢。
為了讓大家更直觀地感受這場變革,小編用更好理解的方式,將前後的差異整理成對比表格:
變革維度 | 傳統搜尋 (Old SEO) | 未來的 AI 搜尋 (New GEO) |
輸入方式 | 單純的「關鍵字打字」 | 支援文字、圖像、長影片與分頁的「多模態對話」 |
頁面呈現 | 10 條藍色網站連結 (Blue Links) | 超過 50% 頁面由「AI Overviews 摘要」與廣告攻佔 |
排名邏輯 | 全球用戶看到統一的關鍵字排名 | 結合 Gmail 與日曆的個人化智能,不再有統一排名 |
用戶行為 | 主動點擊外連網站,自己查找答案 | 直接在結果頁面與 AI 連續追問、完成互動 |
運作機制 | 單次、靜態的單一搜尋行為 | 「搜尋代理 (Search Agents)」24小時在背景監控 |
這場改革,讓 Google 從過去被動的「找資料、帶你去網站」,變成主動「幫你整理好答案,甚至幫你做決定」。
SEO 已死?不,正確來說是傳統 SEO 將死
知識型態的改變,對用戶來說,變得更加方便、精準,查出來的資料完全符合個人意圖;但對操作 SEO 的行銷人與企業老闆來說,這無疑是一場巨大的生存挑戰。
先說這次的改革會給 SEO 帶來哪些挑戰:
- 關鍵字優化失效:多模態長尾搜尋成主流
當使用者不再輸入「台北 咖啡廳」這種短關鍵字,而是改成:「幫我找這張照片裡類似風格、而且有插座的台北不限時咖啡廳」,甚至直接丟圖片、影片或語音提問時。
傳統用關鍵字堆疊為核心的 SEO 就會快速失去效果。
因為搜尋的單位,已經從「字詞」變成「意圖」。
- 流量結構改變:AI 代理人取代人類點擊
未來的搜尋流量不只是「人類」親自點進來看,還會有「AI 代理人」在背景進行篩選與判斷。如果網站缺乏結構化資料、語意標記不足、機器可讀性低,那麼 AI 代理人在抓取資訊時會直接忽略你。
- 內容篩選升級:低品質內容直接出局
隨著 Gemini 3.5 Flash 等模型成為搜尋核心,AI 對內容的判斷速度與標準大幅提升。
它能在短時間內區分:
- 哪些是具備權威與實體背景的內容
- 哪些是拼湊、重寫、缺乏價值的資訊農場
沒有進入 Google 知識圖譜的內容,將很難再被引用或曝光。
無論是 GEO 的崛起,還是這次 Google I/O 大會丟下的震撼彈,都讓行銷圈充滿了焦慮,網路上也鋪天蓋地出現「SEO 已死」的言論。
但,這真的是事實嗎?
不!不要忘記了,不論是 AEO 還是 GEO,它們都是建立在 SEO 的基礎之上。
SEO 只是迎來了轉型。接下來,我們必須重新調整思維,未來的 SEO 優化方向應該是:
從過去爭奪前幾名、堆疊關鍵字的手法,轉變成優化結構化資料讓網站可以進入「AI 引文標籤」、經營品牌聲譽。
那麼,在這個「實體與聲譽」重於關鍵字的 AI 搜尋時代,行銷人到底該如何幫網站拿到 AI 摘要的入場券?
答案的底層核心,就藏在 Google 已經佈局超過十年的核心技術——「知識圖譜(Knowledge Graph)」中。
知識圖譜是什麼?為何近年越來越重要?
知識圖譜是什麼?
如果要用一句最好懂的說法:『知識圖譜(Knowledge Graph)』就是把「資訊」變成「能被理解的知識」的方式。
它不像資料庫那樣堆一大堆資料,而是替搜尋引擎畫出一張「語意地圖」。
地圖裡有三個基礎件:
- 實體(Entity):可被點名的人、品牌、產品、地點
- 屬性(Attribute):這個實體有哪些特徵
- 關係(Relationship):實體和實體之間的連結

它的重點不是記資料,而是讓搜尋引擎能回答更像人類的問題,例如:
- A 跟 B 有沒有關係?
- 這些資訊是不是同一組?
- 使用者到底是在問什麼?
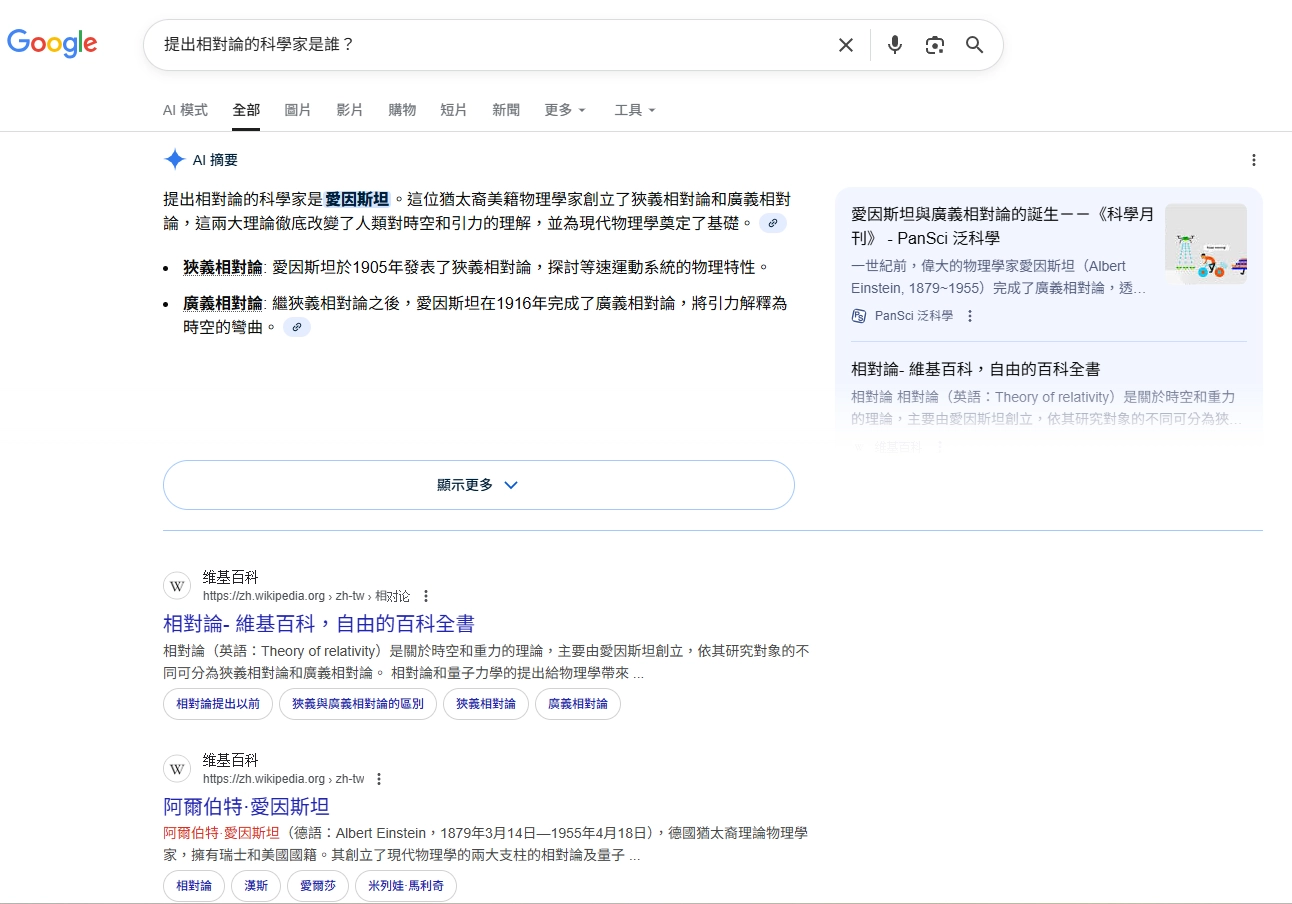
所以你搜尋「提出相對論的科學家」,Google 不需要看到「愛因斯坦」四個字,也能直接帶你到答案。因為在圖譜裡,相關的語意線都已經接好。
- 愛因斯坦(人物) → 提出 → 相對論(理論)
- 愛因斯坦 → 出生地 → 德國烏爾姆
- 愛因斯坦 → 得獎 → 1921 諾貝爾物理獎
為何近年知識圖譜越來越重要?
老實說,它不是突然變潮,而是整個生態一起往前推。以下三件事同時發生:
搜尋從「看字」變成「理解」
Google 在 Hummingbird(知識快如蜂鳥) → RankBrain → BERT → MUM 的 演進過程 核心只有一件事:它想懂你的意圖,而不只是看你打了哪幾個字。
但要懂,就需要語意結構,不是模型自己瞎猜;這就是知識圖譜的作用——它幫搜尋引擎建立穩定的推理邏輯。
- 「皮秒」這個字,實際意圖可能是「皮秒雷射用途」;
- 「學測放榜日期」這類查詢應該對應到「事件」;
- 「黃仁勳 國籍」不是字串比對,而是查某個實體的屬性。
也因此 搜索結果頁(SERP)才會越來越「像答案」:
- 右側知識卡
- 直接摘要
- AI Overview
UI 的變化只是表面,背後都是語意理解能力其實也在變強。
2.大型語言模型(LLM)雖然很強,但沒有「世界地圖」
GPT、Gemini、Claude 這些模型講話流暢得像真人,但有一個弱點:它們不是真的知道世界怎麼組成的。
最常見的狀況就像——司機會開車,但他車上沒導航。
沒有導航會怎樣?
- 路標看錯
- 把兩條路當成同一條
- 明明不確定,卻講得很肯定
知識圖譜補的,就是 AI 最缺的那塊「地圖」:
- 城市在哪?
- 哪些路能通?
- 哪些資訊不能搞混?
- 什麼資訊能互相驗證?
因此現在 RAG、KG 才會聯合上場,而目標只有一件事:讓 AI 的答案不再亂飄、產出內容更可靠。
品牌的「可被識別性」變成 SEO 核心戰場
現在 SEO 不是只有「文章寫得好不好」,而是 Google 能不能清楚知道:
- 你是誰?
- 你跟哪些主題高度相關?
- 外部世界是不是都一致地描述你?
這些訊號會決定:
- 你有沒有機會出現在 Knowledge Panel
- AI Overview 會不會引用你?
- Google 會不會把你視為某主題的「實體」?
簡單說:SEO 已經不是搶字,而是搶著「被理解」。
知識圖譜的核心結構
知識圖譜的基本概念、運作邏輯
把知識圖譜想成三件很直覺的小事:
- 先認出誰是誰(實體)
- 再補上實體的資訊(屬性)
- 最後把實體彼此連起來(關係)
這三步加在一起,就是「語意邏輯」,搜尋引擎與 AI 之所以能推理,就是靠這個邏輯在撐。
三元組(Triple)是知識圖譜的語法
說白了,三元組(Triple)就是知識圖譜的語法。它很像三格句子:
- 主體(Subject)— 關係(Predicate)— 客體(Object)
舉個例子:
愛因斯坦(主體)— 提出(關係) — 相對論(客體)

或像這樣:「iPhone 15 的品牌創辦人是誰?」→ 由 iPhone 15 → Apple 再跳 Apple → 創辦人Steve Jobs
- 台灣 — 位於 — 亞洲
Triple 的意義不在格式,而在「可推理」;它讓搜尋引擎處理跨頁、跨段、跨來源的問題時不用靠猜。
RDF、OWL 是什麼?為什麼是知識圖譜的語意標準?
如果說三元組(Triple)是知識圖譜的句子,那 RDF 與 OWL 就是這個世界的「文法規則」。
- RDF(Resource Description Framework):統一描述方式,讓「大家講同一種語言」,避免 A 寫「出生地」、B 寫「出生於」、C 寫「place_of_birth」。
- RDF 把這些通通規範成能被機器共用的格式,所以 Google 才能把:人物資料、維基百科、品牌官網、新聞、政府資料…等,全部串成同一張語意網。
- RDF 把這些通通規範成能被機器共用的格式,所以 Google 才能把:人物資料、維基百科、品牌官網、新聞、政府資料…等,全部串成同一張語意網。
- OWL(Web Ontology Language)比 RDF 再進一步,補上邏輯規則(分類、屬性、階層…等)。
- 例如:「父母」是一種「親屬關係」、「醫生」是一種「職業」、「蘋果」既可以是「品牌」也可以是「水果」,但兩者屬性不同。
- OWL 讓這些分類、層級、語意差異可以被寫進邏輯裡,好讓搜尋引擎能做推理;OWL 讓資料之間「不只相連」,還能「有邏輯」!
標準 | 它在做什麼 | 重點 |
|---|---|---|
RDF | 描述實體與關係 | 統一格式,讓機器都看得懂 |
OWL | 描述規則與語意邏輯 | 讓搜尋引擎能推理、能分類 |
兩者一起構成搜尋引擎的語意基礎,因此 Google 才能在沒有看到「愛因斯坦」四個字的情況下,依然給出「是誰提出相對論」的正確答案。

如何提升你在知識圖譜中的存在感?
這裡只保留最能影響 SEO 的六件事。
1.先決定你是什麼 實體(Entity)
若你希望網站能被加入知識圖譜,你得先回答一個問題:你希望 Google 把你當成什麼?
是品牌?媒體?還是專家?或是哪個分類主題的權威站點?
這些 Google 沒法替你猜,若定位不明,就很難被放進實體節點。
2.替重要頁補上 Schema(語意標記),讓搜尋引擎更容易理解你
Schema 不是為了「加程式碼」而存在,它更像是你的語意「身份證」,功能是:
- 告訴 Google:你是哪種類型的實體?
- 補足「頁面 → 主題 → 實體」的語意連結;
- 強化 Google 對你內容的信任程度。
建議至少補上:Organization(組織)、LocalBusiness(在地商家)、Article(文章類型)、FAQ(常見問題)、Product(產品資訊)、Person(若你是個人品牌)。
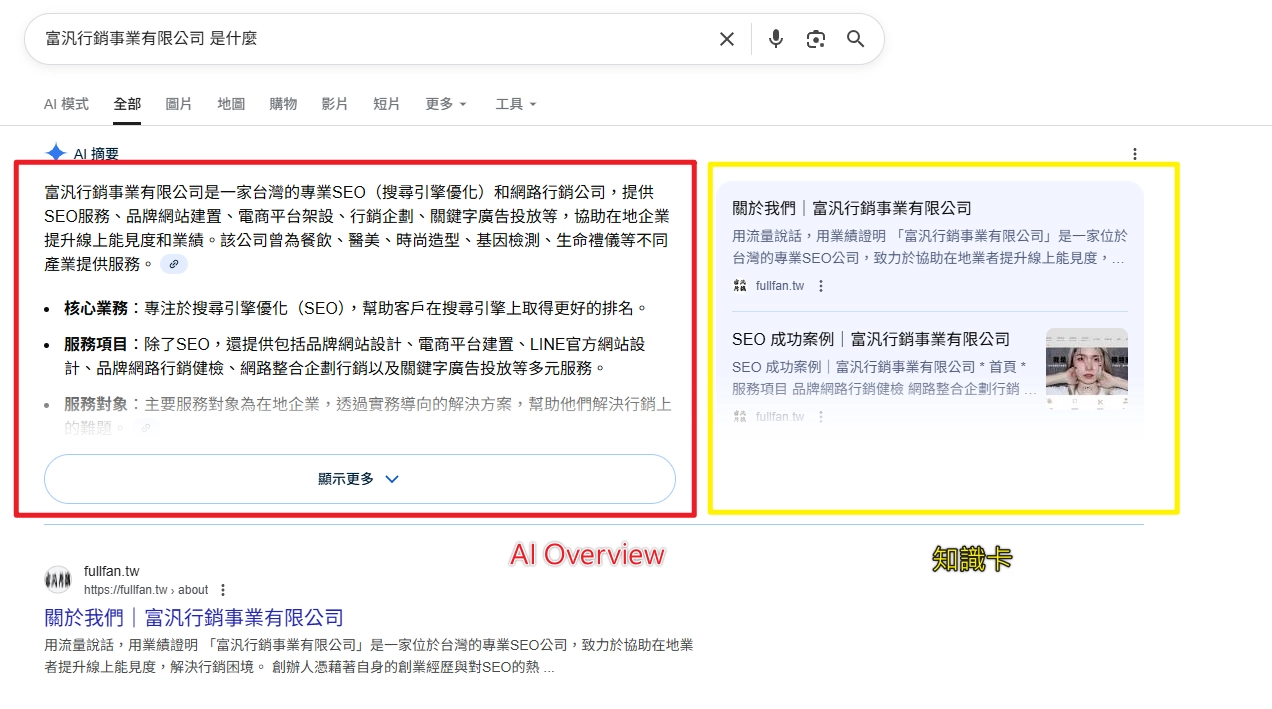
3.統一你的品牌名稱與 NAP
假設我們的品牌在網站寫「富汎行銷」,FB 寫「富汎行銷有限公司」,Google Maps 寫「富汎行銷股份有限公司」,那 Google 會很困惑,不知道該把哪個視為同一個實體。
結果就是:知識圖譜不敢把資料合併 → 可見度直接下降,所以這裡要記住一個原則:內容越一致,越容易被 Google 納入知識圖譜。
4.用「SameAs」串連你的外部權威來源
SameAs 像知識圖譜的高速公路,簡單說就是:讓 Google 一次把你所有網路足跡串成同一個人(品牌)。
常用的 SameAs 平台:
外部平台越一致,Google 越能確定你的「實體存在」。
5.內容裡自然寫出「實體句」與「關係句」
這部分非常關鍵,也是大部分 SEO 寫手忽略的。知識圖譜依賴的不是關鍵字堆疊,而是「語意關係」。
文章中可以自然加入:
- A 是什麼?
- A 屬於什麼?
- A 跟誰相關?
- A 有哪些屬性?
這種類似「百科式」的句子,最容易被語意網抓到。
例如:
- 傳統 SEO 會寫:「皮秒雷射效果好嗎?」
- 為了辨識實體 Entity SEO 建議改寫為:「皮秒雷射是一種醫療設備,主要用途是處理色素、改善膚況,由皮秒能量作用於皮膚組織。」
這類句子能被知識圖譜讀懂,也比較容易進 Featured Snippet 或 AI Overview。
6.外部提及越一致,你越容易被 Google 認得
說白了,知識圖譜最看重的一件事是:全網是不是一致地描述你?
如果全網都使用相同名稱、同樣描述、同樣連結方式,Google 會更快把你視為「可確認的實體」。
知識圖譜不是炫技,而是讓 Google 真的看懂你
如果把以上濃縮成一句話:強化實體 → 明確關係 → 外部一致 → 就能進入知識圖譜,也更容易被搜尋引擎信任。
做到這些,你會更容易出現在:
- Knowledge Panel
- Featured Snippet
- AI Overview
- 以及 E-E-A-T 的整條語意鏈
這些就是未來 SEO 的主戰場。
知識圖譜和SEO有什麼關聯?
一句話:知識圖譜決定 Google 能不能理解你,理解你之後,才輪得到 SEO 發揮作用。
知識圖譜 和 SEO 的關聯主要有三個:
- 實體能不能被 Google 看懂?
- Google 不再只看字,而是看你是不是一個「明確的實體」?
- 被看懂=能進知識卡、AI Overview、有更高信任度。
- 關係越清楚,E-E-A-T 越高!
- 你的品牌、作者、主題如果在網路上描述一致、被引用,Google 就會把你標進知識圖譜,權重提升得比堆字快得多。
- 你的品牌、作者、主題如果在網路上描述一致、被引用,Google 就會把你標進知識圖譜,權重提升得比堆字快得多。
- SEO 已經從「關鍵字比賽」轉向「語意比賽」
- Google 想的是:你的內容在講「哪些實體」,以及「它們之間有沒有邏輯」;這也決定你能不能進入精選摘要與 AI 結果頁。
簡單說:知識圖譜是 SEO 的地基,沒有這塊,後面所有的排名策略都站不穩。
為什麼知識圖譜會成為下一輪 SEO 的底層邏輯?
只要你的品牌、內容、產品,都能清楚標示實體、屬性和關係,搜尋引擎自然會把你放進正確的位置;懂知識圖譜,就是讓 SEO 回到本質──可被理解、可被驗證。
台灣人的新偶像,黃仁勳也說了,這3年內所有產業的一切都會劇烈變化,但重點是:你只要抓住事情的底層邏輯,就可以面對這些變化。
剛好知識圖譜,可以說是 AI 在語義理解、個體元素拼湊中的底層邏輯,你只要好好的掌握知識圖譜相關的優化技術,相信在這幾年內,就算 AI 的影響再劇烈,你的網路行銷也可以做的順風順水、大展鴻圖。
知識圖譜的常見問題
Q1:知識圖譜跟資料庫有什麼差別?
資料庫是在「存資料」,而知識圖譜是在「解釋資料」。
一個是把資訊放進表格;另一個是把資訊之間的關係建成結構。
SEO 會重視知識圖譜,是因為搜尋引擎需要的是「理解」而不是「紀錄」。
Q2:不懂程式,也能做 SEO 嗎?
可以。
實務上,網站主只需要做到三件事:
- 把內容拆成實體(人、品牌、產品)
- 明確標示屬性(規格、時間、價格、作者)
- 用內外部連結補上關係
你不需要寫程式,但需要知道內容怎麼被「被機器讀得懂」。
Q3:知識圖譜會直接提高排名嗎?
它不是「開了就加分」的工具,而是 Google 理解內容的基礎。
排名是演算法決定的,但「能不能被理解」是入場券;如果你的網站實體不清楚、關係模糊、外部資料不一致,搜尋引擎根本不會把你排進正確的領域。
Q4:小型網站也需要知識圖譜嗎?
需要。
因為知識圖譜不是大網站的專利,而是「讓 Google 認識你」的方法。
只要你的網站包含:
- 品牌
- 人物
- 產品
- 服務
就一定會被當成「實體」;實體越清楚,SERP 越容易顯示你。
Q5:知識圖譜和 AI Overview 有什麼關係?
AI Overview 不是「重新爬 Google」,而是讀現有的實體、屬性與關係,再整合答案。
換句話說:你的知識圖譜越清晰,被 AI 摘要引用的機會就越高;反之,如果你沒有提供明確的語意結構,AI 會找其他相關來源提供答案。
Q6:要怎麼知道 Google 是否已收錄我的實體?
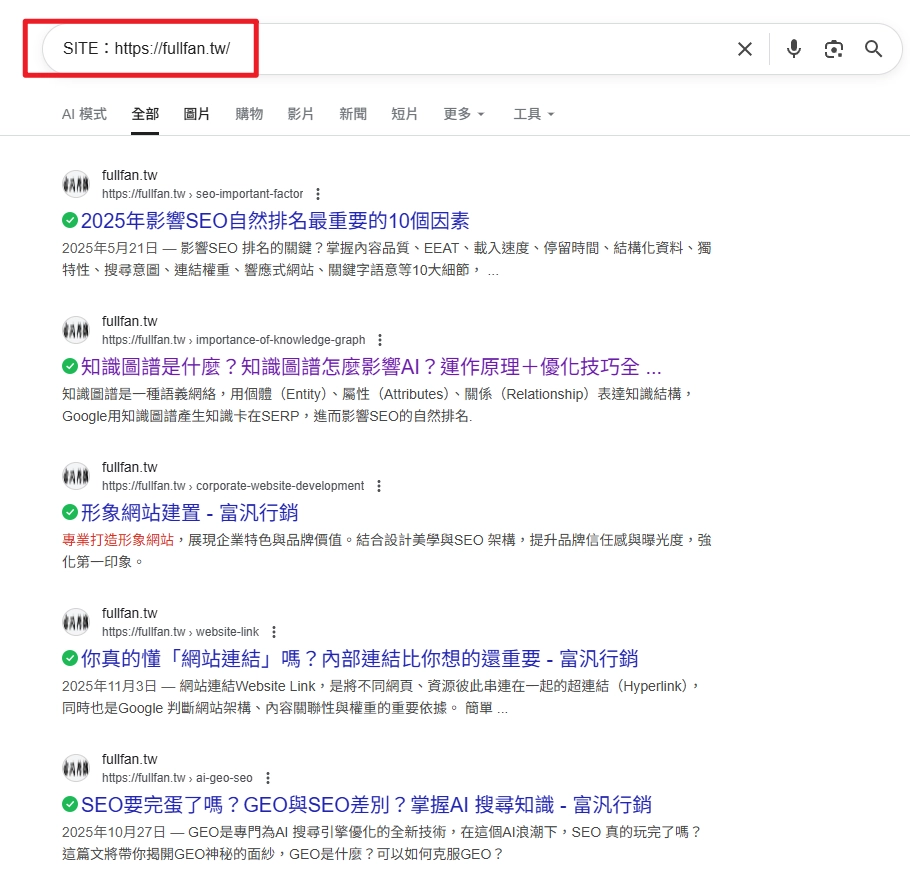
有三個簡單方法:
- 搜尋「你的品牌名 + 知識卡」看是否出現右側 Knowledge Panel
- 搜尋「品牌名 + 是什麼」看 Google 是否能回答
- 用 Site: 查詢是否能看到一致的實體資訊
如果 Google 的回答非常模糊,代表你的實體資料還不夠清楚。